I frontloaded my classes to heavily at Brandeis, and coming into my Junior Spring Semester, I had completed the majority of the coursework requisite for my majors. During that semester, as most of my friends were abroad, I decided to work on a side project for the semester, accompanied only by a French class requisite for my graduation. This was one of the best decisions of my life.
CalcU emerged from a need I saw when tutoring. I was a math tutor throughout highschool and into part of college, and I frequently helped out folks who were tangentially studying math (Biology, economics) and needed refreshers on material far before the material they were trying to apply. A student who needs calculus for bioinformatics forgets basic derivative rules, a student in microeconomics forgets the basics of geometry, a student in multivariate calculus has never taken linear algebra.
Students in this position need a resource which has a plethora of examples, sample questions and explanations, but more importantly, they need a resource that is able to quickly determine what they know, what they do not know, and what they are trying to learn. CalcU sought to fill this niche.
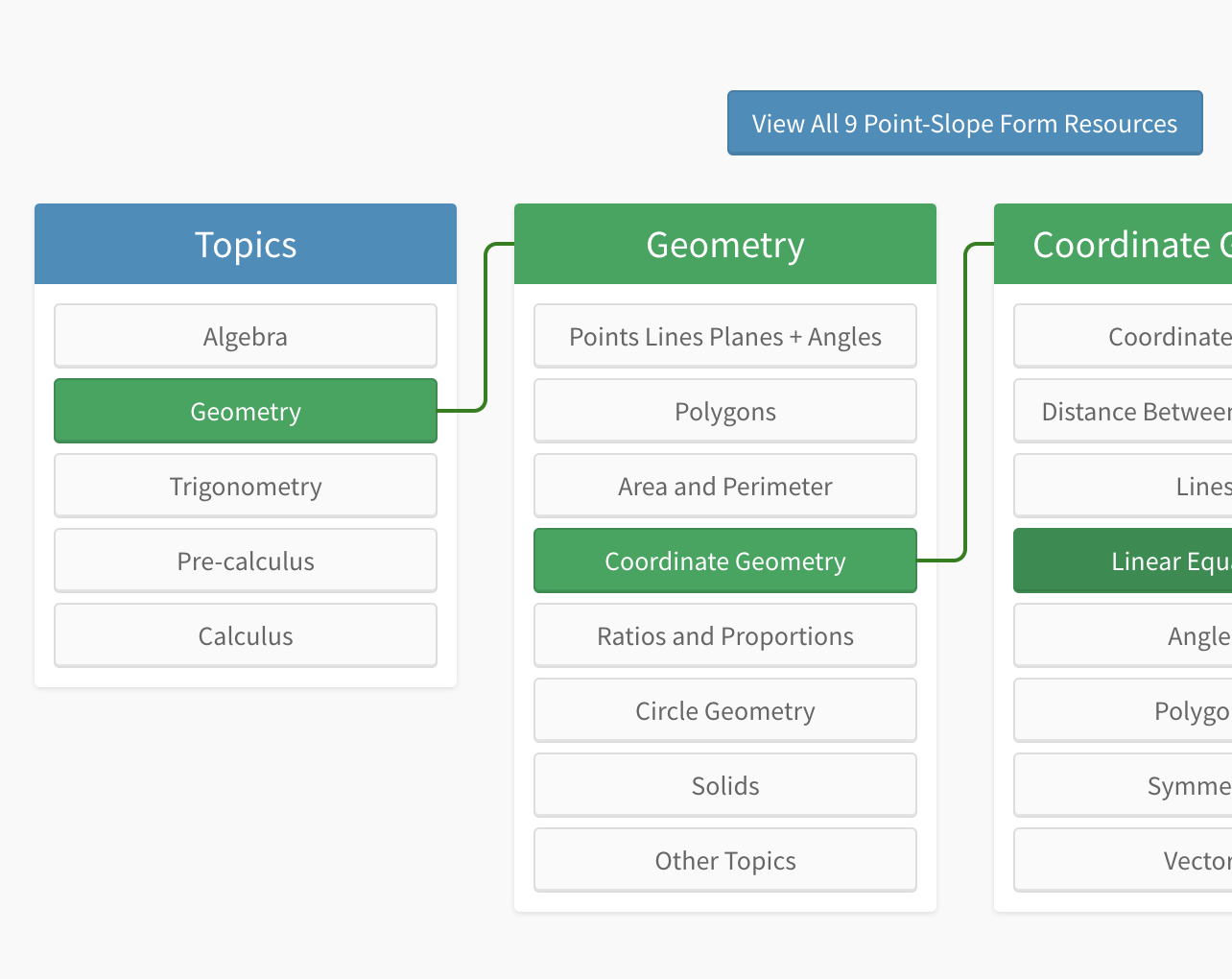
The project expanded when I got a grant to continue the work over the summer before my Senior year, and with the funding was able to hire three interns. The fundamental premise was that we used web-scraping to get the data from a large number of open source text books (including problems, examples, solutions and explanations). We then used manual categorization into a taxonomy of problems that we created. This taxonomy was both recursive and strongly ordered. A student’s familiarity with different areas of the taxonomy was recursively explored through a placement quiz which sought to understand the set of problems the student understood and those that they did not. CalcU built a rating system to enable the best examples and problems to drift toward the top, and had the ultimate goal of identifiying learning styles and common patterns among learners that would enable machine prediction of the next problem a student should see.
I could talk about CalcU for days, but I will not.
CalcU was my first big independent project, and I loved it. It showed me how much fun desigining and building a system from scratch can be. It taught me more than I can say about how to manage coders - particularly those hungry to learn. It made me believe that I am capable of building big, complicated, and technically complex systems. It was the project that enabled me to identify as an engineer.
It ultimately failed. The system and software are good at what they do. They are built in a way that minimizes server costs, and are fairly well exposed for future data science work. However, I failed to generate the enthusiasm about the system that I had hoped. I did the classic engineering mistake of building without consulting real users: trying to present a polished end result without thinking about whether it is what people wanted/needed/could be familiar with. I avoided pushing the software into the hands of users because I was afraid of what they would think, and by the time I was satisfied with it, it was too rigid to enable valid user feedback to influence the final product.
I am deeply thankful for the experience that CalcU gave me. The folks I got to work with (students and teachers in the high-schools, the faculty at Brandeis who advised me (Profs. Torrey and Hickey), and my friends and interns Sofia, Russ, Roger and Danny) made it one of the most fun and exciting projects I’ve ever worked on.
I hope to work more in this space in the future, and learn from the ups and downs of the time I spend on this project.I could talk about CalcU for days, but I will not.